샤딩이란?
데이터를 분산하여 저장하는 개념
한대의 서버에 빅데이터를 저장하게 되면 I/O가 한대에서 일어남.
서버를 여러 개를 두고 분산 저장한다면 I/O 가 여러 대에서 일어나기 때문에 효율이 좋아짐.
샤딩의 목적
- 데이터 분산- 데이터를 분산하여 순차적으로 저장한다면 한 대 이상에서 트래픽을 감당하기 때문에 부하를 분산하는 효과 있음
- 백업과 복구 전략- 미리 데이터를 분산하여 저 정해둔다면 리스크로부터 보호받고 효과적인 시스템 운영이 가능해짐
- 빠른 성능- 여러 대의 독립된 프로세스가 병렬로 작업을 동시에 수행하기 때문에 이상적으로 빠른 처리 성능 보장
mongodb 샤딩 구성요소
Shard
- 분산된 데이터 저장 공간
Mongos
- 라우트 서버로 해야할 일 (빅데이터를 처리하는 일) 샤드 서버한테 알맞은 일을 분배해줌(즉, 올바른 각각의 요청된 일을 알맞은 샤드로 라우팅 하는 기능을 하는 곳)
Config servers
- 샤드에 대한 메타 데이터 저장(인덱싱)/관리
메타 데이터란?
실제 데이터가 아니라 목차라고 생각하면 됨. (인덱싱)
이해한 것 정리
컴퓨터
cpu : 연산처리 (저장 시 일이 없음)
ram : 임시 저장 장치
몽고 디비는 하드가 아니라 ram에 저장하는 게 목적
램에 저장하고 컴퓨터를 끄면 데이터는 날아간다.
하지만 데이터가 날아가면 안 되기 때문에 램이 쉬는 시간에 하드디스크에다가 저장시킨다.
이 내용을 분산 저장하게 되면 굉장히 빨라짐(일을 나눠서 하기 때문에)

위 그림을 보자
- 저장해야할 데이터가 1~9까지 있다.
1 ) 나는 이것을 빠르게 처리하고 싶다. 그럼 어떻게 해야 할까?
→ 답은 분산 저장이다.
분산 저장은 1~9까지를 3개로 (123,456,789) 나눠서 저장하면 일을 나눠서 하는 것이다. (때문에 빠름)
123,456,789는 같은 데이터가 아니라 다른 데이터를 가지고 있기 때문에 분산 저장이라고 한다. (오해 : 복제가 아님)
2 ) Mongos(라우터 서버)는 어떻게 일을 분배해줄까? 만약, 클라이언트가 5번은 어디에 있어라고 물으면 라우터는 어떻게 정보를 알 수 있을까?
→ 답은 Mongos가 Config Server에 정보들을 저장(인덱싱) 해둔다.
※ 정보들 - 메타데이터(실제 데이터가 아님 -> 목차라고 생각하면됨.)
라우터가 하는 일은 클라이언트에게 받은 요청된 일을 분배해서 이동 시킨다.
그러기 위해서는 라우터는 샤드에 어떤 것들이 정보들이 있는지 알아야 한다.
Mongos(라우터 서버)는 Config Server에다가
1~3의 데이터 - A, 4~6 데이터 - B , 7~9 - C 인 이 정보들을 인덱싱 해둔다.
(예) 목차를 들고 있는 것.
그래서 만약 5번을 찾는 요청이 라우터에게 들어올 경우
1 ) Mongos(라우터 서버) → Config Server에게 5번은 어딧는지 요청한다.
2 ) Config Server → Mongos(라우터 서버)에게 5번은 B에 있어라고 응답한다.
3 ) 그런데 Mongos(라우터 서버)는 바로 데이터를 찾으러 가지 않고 Config Server에 메타데이터를 저장하고 찾으러 갈까?
Mongos(라우터 서버)는 요청된 일을 분배하여 이동시키는 일을 하기 때문에
데이터를 찾는 일 까지는 하지 못한다. 한다고 하면 아마 속도가 느려질 것이다.
그래서 Config Server에 메타데이터(데이터를 찾기 위해 어디로 가야하는지의 정보(목차))를 저장하여 요청하는것이다.
위 그림에서는 데이터의 복구가 안된다는 문제점이 있다.
그 문제를 얘기하기 전에 RDB에 있는 UNDO와 REDO에 관해 알아보자.
RDB에는 UNDO와 REDO가 있다.
RDB에 존재
- UNDO : 복구 (원상태 롤백)
- REDO: 복구(실패 시 재시도)
UNDO와 REDO가 있어서 RDB는 데이터가 안전하다.
하지만 몽고디비에는 UNDO와 REDO (존재 X) → 트랜잭션 관리가 안됨
(즉, 일의 단위가 있는데 하다가 중간에 실패하면 그 부분만 안되고 이전꺼는 다 실행이 되는 일이 발생)
→ 때문에 DB가 보장되지 않음 = "정보가 100% 정확하지 않다."
→ 그래서 이런 경우 프로그래밍으로 처리를 하면된다
(try catch같은 것으로 실패했을경우 다시 업데이트아니면 인서트 시켜줌)
하지만 몽고 디비가 데이터를 보장해주지는 않는다.
만약, 위 그림과 같은 구성에서 10을 저장한다고 할때, 실패할 경우 10이라는 데이터가 사라지게 되며,
프로그램쪽으로 실패한 응답을 받게되면서 다시 save를 해야한다 → 프로그래밍으로 처리 할 수 밖에 없는가?
→ 답은 아니다. 그 방법은 맨아래에 설명함.
1) 위 그림 구조1 대로라면 서버가 하나라도 망가지면 시스템 전체가 망하는 문제점이 있다. 어떻게 해결할까?
→ 리플리카라는 복제 방법이 있다.
서버들이 각각 3개씩 복제된 상태에서
→ 1번 서버가 무너짐 → 2번서버가 돔 → 2번서버가 돌동안 1번서버는 복구에 들어감
→ 1번과 2번 두개의 서버가 무너짐 → 3번 서버가 돔 → 1,2번 서버는 복구에 들어감.
따라서 서버를 여러개 복제하여 대비하는 "리플리카" 가 있기 때문에 문제를 해결 할 수 있다.
리플리카를 만들 때는 3개를 한쌍으로 만든다.
이 3개를 묶어 리플리카 셋(SET)이라고 한다.
이러한 과정을 데이터가 RAID된다고 한다.
※ RAID(Redundant Array of Independent Disk : 독립된 디스크의 복수 배열) :여러개의 디스크를 묶어 하나의 디스크 처럼 사용하는 기술

만약, 10이라는 데이터를 저장 할 경우
→ 10이 들어옴
→ Primary Server의 MongoS가 10을 저장하라는 요청을 받음
→ Primary Server의 Config Server에게 어디에 작업해야할지 요청 함
→ Config Server가 Primary Server의 MongoS에게 "A Server(123)로 가서 작업해" 라고 응답함
→ Primary Server의 MongoS가 10이라는 데이터를 바로 "A Server(123)" 에 저장시키는것이 아니라
UNDO,REDO처럼 OPLog(저장 영역)라는 것이 있는데 거기에 10이 들어오면 OPLog에 저장이라는 오퍼랜드가 들어옴
(즉 A Server(123)의 OPlog(Operation log)영역에 10이라는 데이터를 저장하는 명령어가 저장)
→ OPLog에 저장됨 (여기서 10이 저장되는것이 아니라 10이라는 데이터를 저장하라는 명령어가 저장됨)
2) 나머지 세컨더리 서버에는 10이 어떻게 될까?
→ Primary와 Secondary에 각각 연결된 OPLog 끼리 서로 통신을 함 (서로 리퀘스트를 함)
이유는? 동기화하려고 (복제해야하니깐 동기화해야함)
※ 예전에는 Primary는 Master, Secondary는 Slave라고 하였지만 주인과 노예라는 의미때문에
프라이머리와 세컨더리로 바꼈다고 한다.
서로 통신하는 순서
→ OPLog끼리 리퀘스트를함
→ 새로들어온 오퍼레이션이 있니?
→ 응답 있어 하면 10이라는 명령어 저장
이과정을 HeartBeat 라 한다.
HeartBeat는 그물처럼 서로 연결되어져 있다.
3) 계속 리퀘스트하면서 서로 물어봐야하나???
→ request하는 시간을 폴링(polling)이라고함
- default time이 존재한다
- default time은 2초 단위로 수행한다.
※ 폴링(polling)이란?
하나의 장치(또는 프로그램)이 충돌 회피 또는 동기화 처리 등을 목적으로 다른 장치(또는 프로그램)의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 송수신 등의 자료처리를 하는 방식을 말한다.(위키 백과)
※ 참고
http://mongodb.citsoft.net/?page_id=102
The replica's synchronization and master election of MongoDB | MongoDB Internals
MongoDB의 복제 동기화 및 마스터 선출 글 : 이승용 MongoDB의 복제 시스템에서 대해서는 앞 절에서 살펴보았다. 복제는 시스템의 Fail-Over를 제공하기 위한 분산시스템의 핵심 기술로 자리잡고 있다.
mongodb.citsoft.net
RDB의 REDO를 어떻게 대신하여 복구할 까?
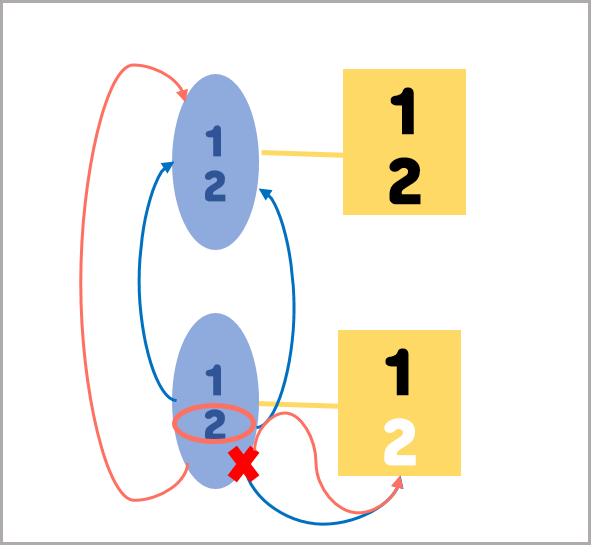
위 그림에서 Primary Server에는 1,2가 저장되었고 Secondary Server에는 1만 저장되어 있는 상태이다.
OPlog에는 1,2 모두 저장하라는 명령이 들어와 있고, P와 S Server 데이터를 비교하여 2가 저장되어 있지 않은 것을 확인하고 OPlog에서 명령을 다시 재실행한다.
이 때, 실패하게 되면 S Server와 연동된 OPlog의 내용은 사라지게 되고 P Server와 연동된 OPlog 와 heartbeat하여 동기화 한다.
그리하여 다시 1,2를 다시 저장하라는 명령이 들어오면 명령을 실행한다
이과정을 명령이 성공할 때까지 실행한다. 즉 RDB의 REDO가 되는 것을 볼 수 있다.
RDB의 UNDO를 어떻게 대신하여 복구할 까?

위 그림에서 처럼 19.99초에 heartbeat가 수행되었고 20.00초에 Primary OPlog에 2를 5로 수정하라는 명령이 들어왔다고하자.
이 명령이 수행되어 Primary Server의 2가 5로 변경된다. 다음 heartbeat는 21.99초에 수행되어 2를 5로 수정하라는 명령을 받는다.
그러나 21.55초에 Primary Server와 OPlog가 고장났다고 하자.
이렇게 되면 남은 두 개의 Secondary Server 중 하나가 선출되어 Primary Server가 되어 두 개의 Server로 운용된다.
이 타이밍에서 다른 클라이언트가 5 데이터를 요청하면 확인할 수 없다. → 지금은 데이터 복구가 안된다.
10초 정도 후, 기존의 primary server가 살아나게 되면 자동으로 Secondary Server가 된다.
서로 heartbeat를 통해 동기화를 진행하여 Operand가 기준이 되어 2가 5로 수정되는 명령이 모두 들어온다.
( 복구가 된 이후 )
heartbeat의 polling 시간을 매우 짧게 진행하여 이러한 문제를 방지할 수 있으나 MongoDB에 과부하가 발생한다.
따라서 시간을 줄이는 방법보다, 저널링이라는 시스템을 통해 복구를 진행한다.
※ 저널링 파일 시스템 : 변경사항을 반영하기 전에, 변경사항을 추적할 수 있는 어떤 데이터를 보관하는 시스템
타이밍 : OPlog에 2를 5로 수정하라는 명령이 들어와 수행직전에 파일로 명령을 기록한다.
만일 위의 상황처럼 서버가 죽어버린 경우, 저널링부터 찾아가 Operand가 같은지 확인하고 다르다면 동기화시킨다. 이를 저널링 시스템이라고 한다. 또한, 클라이언트의 요청에도 문제가 없다.
샤딩 실습
2021.12.05 - [DataBase/MongoDB] - [ MongoDB ] 샤딩 (Sharding)시스템 구성 실습
[ MongoDB ] 샤딩 (Sharding)시스템 구성 실습
(실습) 4개의 shard를 만들어 샤딩함 샤딩의 개념을 모르겠을 경우 2021.12.04 - [DataBase/MongoDB] - [ MongoDB ] 샤딩(Sharding)이란? [ MongoDB ] 샤딩(Sharding)이란? 샤딩이란? 데이터를 분산하여 저장하는..
dev-cini.tistory.com
'DataBase > MongoDB' 카테고리의 다른 글
| [ MongoDB ] 샤딩 (Sharding)시스템 구성 실습 (1) | 2021.12.05 |
|---|---|
| [MongoDB] 무료 몽고디비(MongoDB) Atlas (0) | 2021.10.19 |